


Oracle Cloud Infrastructure offers many AI-related services such as Anomaly Detection, Language, Speech and Vision.
Today I wanted to share my first experience with Document Understanding, the most recently released serverless AI-related service that helps developers to extract data from documents such as images & scanned files.
The typical use cases of Document Understanding are OCR (Optical Character Recognition), Document Classification, and various data & table extraction from files such as PDFs, JPGs, PNGs, TIFFs.
Pre-trained models make it possible to start without having to train your own model for uses cases such as recognizing a document type (classifying it), and/or extracting key / values data from specific document types such as passports, receipts, invoices, etc. That being said, on the console, a preview of Key Value extraction and document classification indicates a future possibility of using custom models (i.e. specific to your industry/use case).
The list of pre-trained models can be found here. One of the nice features is the ability to extract tabular data (ie tables) from the documents and keep their row/column structure.
The service can be used in batch mode, and in asynchronous mode (with certain service limits) which is great because it allows processing a high number of documents or documents with a high number of pages.
Oracle Document Understanding can be used via the Console, REST API, SDKs, or CLI.
Let's do the first try from the console... The simple scenario I want to deploy is to classify documents I ingest manually through the console.
A pre-requisite needed for the purpose of this scenario is the creation of an object storage bucket in your destination compartment. This is where the classified documents will sit.
I start by accessing Document Understanding from Analytics & AI.
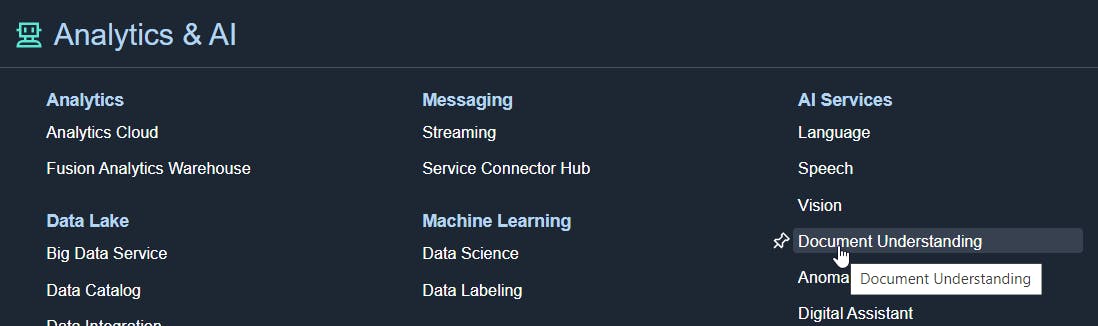
From there, as always with OCI console, I check the region I'm in, and the compartment I'm in otherwise I could get a few unexpected issues :
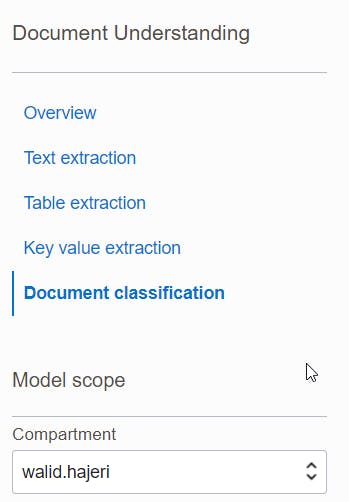
After that, I specify that I want to classify a local file.
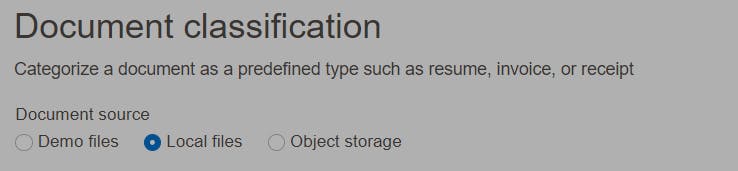
On the right of my screen, If I select the correct compartment, I should see my target object storage bucket :
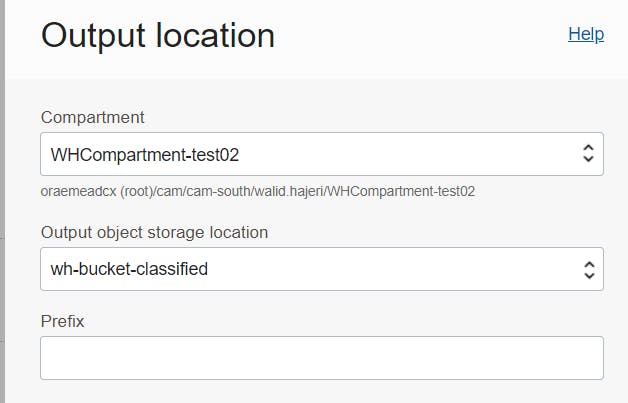
I then enter a prefix: wh-doc-test and realize that my central screen panel changes to allow for a document upload :
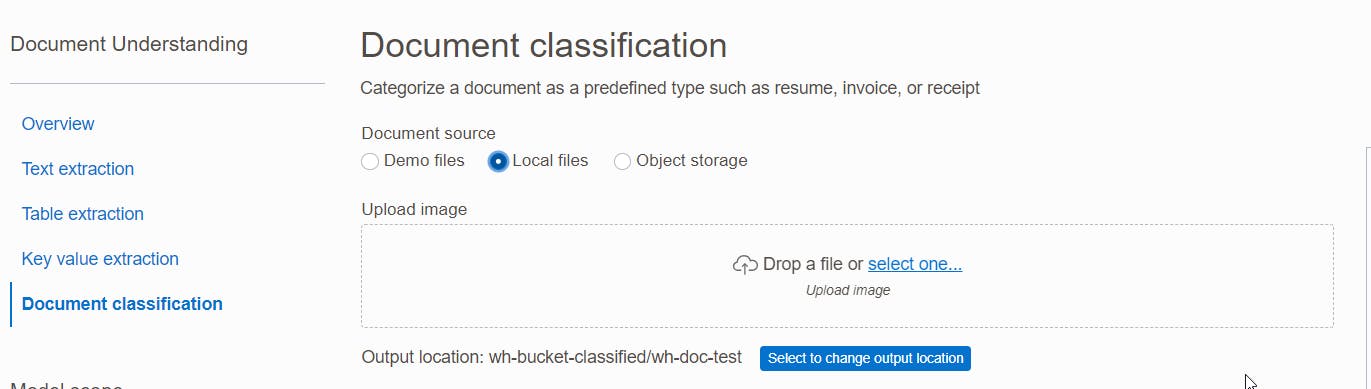
I use this sample tax return document: https://www.irs.gov/pub/irs-pdf/f1040.pdf
From there we get the right classification from the pre-trained model which recognized the tax form:
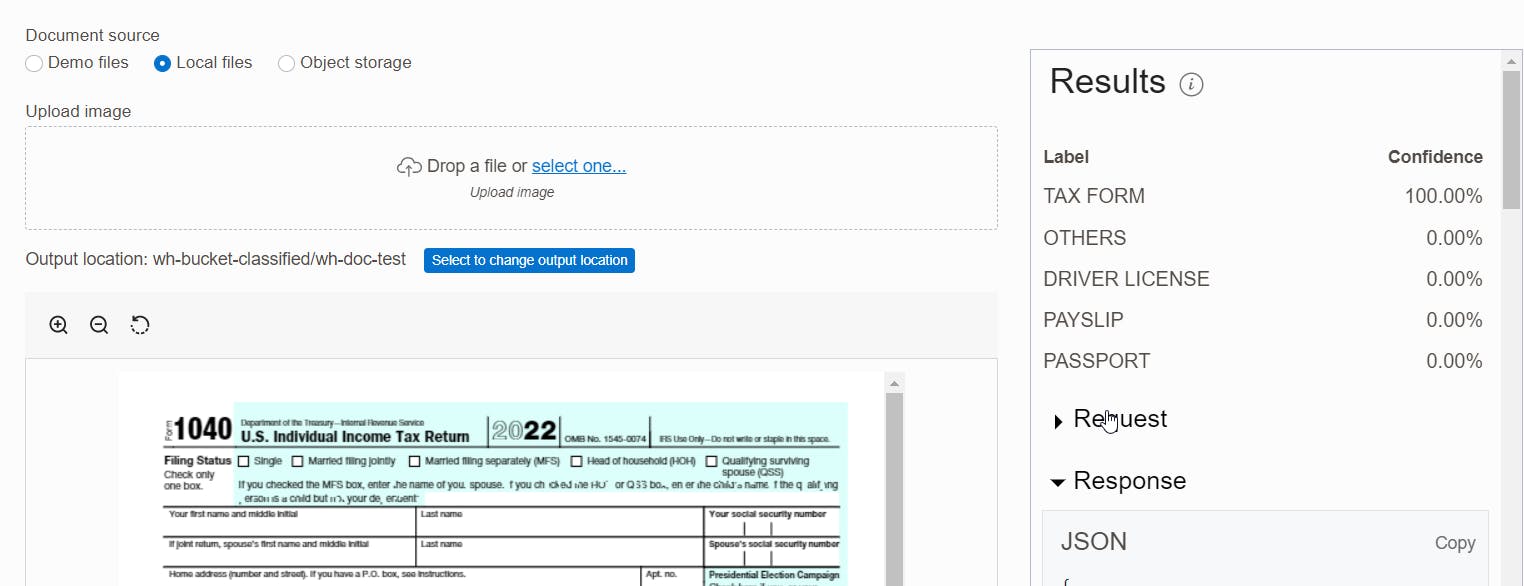
I went to the target bucket to check what was added there and found a json file that gives in a similar way a probability of document type between 0 and 1 for each document page :
{
"documentMetadata" : {
"pageCount" : 2,
"mimeType" : "application/pdf"
},
"pages" : [ {
"pageNumber" : 1,
"dimensions" : null,
"detectedDocumentTypes" : [ {
"documentType" : "TAX_FORM",
"confidence" : 1.0
}, {
"documentType" : "OTHERS",
"confidence" : 6.8732535E-15
}, {
"documentType" : "DRIVER_LICENSE",
"confidence" : 2.3319423E-19
}, {
"documentType" : "PAYSLIP",
"confidence" : 2.0229963E-19
}, {
"documentType" : "PASSPORT",
"confidence" : 3.0984195E-20
} ],
That's it for today! I suggest as next steps to start exploring other functionalities such as key values extractions and text extraction and also to start testing the service via the API.
Walid Hajeri
Disclaimer : Views are my own , none of the ideas expressed in this post are shared, supported, or endorsed in any manner by my current employer.
Photo by Tetyana Kovyrina: link